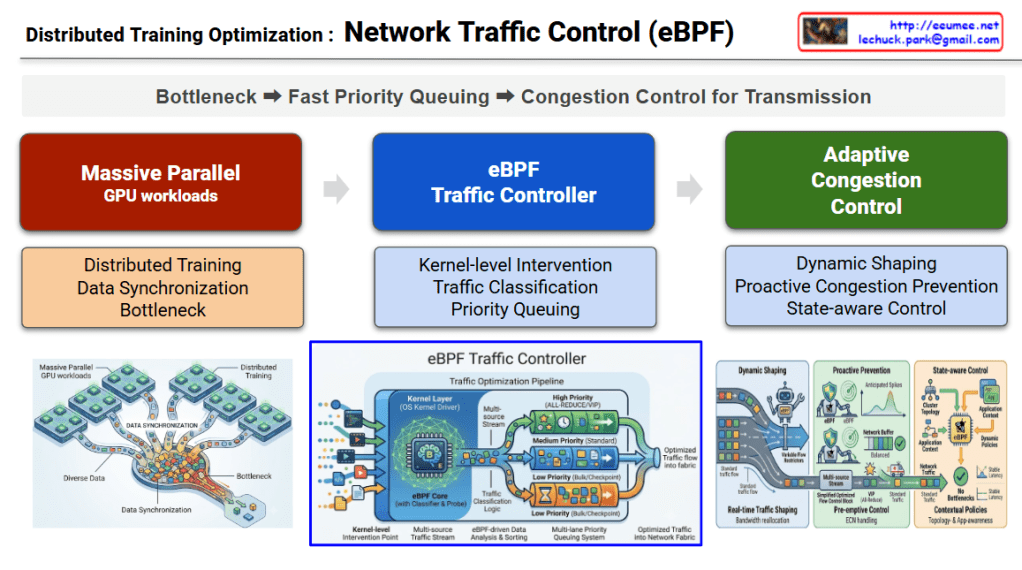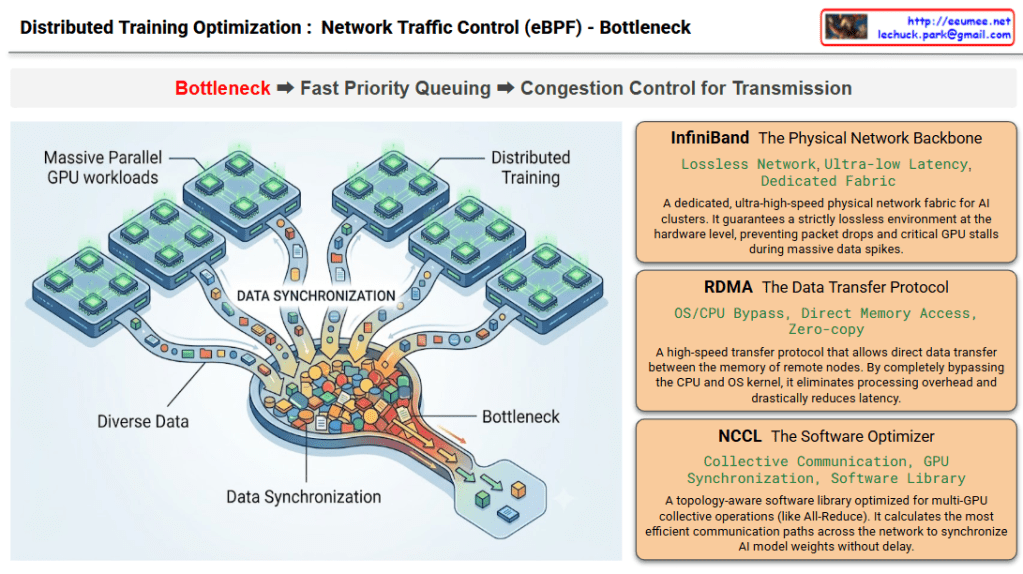
This infographic intuitively visualizes the “Bottleneck” phase—the very first step in network optimization for large-scale AI distributed training environments. It also outlines the three foundational infrastructure technologies involved in this process. As indicated by the red highlight on the word Bottleneck in the top workflow process, this specific diagram is entirely focused on defining the problem area.
1. Visual Context Description (Left Illustration)
- The graphic on the left depicts a Massive Parallel GPU workloads environment, where numerous GPU clusters are operating simultaneously.
- “Diverse Data” pouring out from each distinct GPU node converges into a massive, funnel-like channel labeled “DATA SYNCHRONIZATION.”
- The illustration brilliantly captures a severe “Bottleneck” occurring as a massive volume of data packets (represented by the colorful blocks) attempts to squeeze through this narrow passage all at once, causing a massive traffic jam.
2. Core Infrastructure Technologies (Right Panels) The right side details the three core infrastructure stacks where this physical and logical data synchronization (and the resulting bottleneck) takes place.
- InfiniBand (The Physical Network Backbone): A dedicated, ultra-high-speed physical network fabric for AI clusters. It guarantees a strictly lossless environment at the hardware level, preventing packet drops and critical GPU stalls during massive data spikes as seen on the left.
- RDMA (The Data Transfer Protocol): A high-speed transfer protocol that allows direct data transfer between the memory of remote nodes. By completely bypassing the CPU and OS kernel, it eliminates processing overhead and drastically reduces latency.
- NCCL (The Software Optimizer): A topology-aware software library optimized for multi-GPU collective operations (like All-Reduce). It calculates the most efficient communication paths across the network to synchronize AI model weights without delay.
📝 Summary
This diagram defines the problem state by using a funnel metaphor to visualize the inevitable network bottleneck that occurs when multiple GPUs synchronize data during distributed AI training. Simultaneously, it serves as an introductory technical overview, clearly outlining the keyword-centric roles of the underlying infrastructure stack—InfiniBand, RDMA, and NCCL—that handles this immense traffic.
#AIInfrastructure #DistributedTraining #NetworkBottleneck #DataCenter #InfiniBand #RDMA #NCCL #GPUCluster
With Gemini